【论文】Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection
论文题目:Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection
作者:Shi-Xue Zhang, Xiaobin Zhu, Chun Yang, Hongfa Wang, Xu-Cheng Yin
会议/时间:ICCV2021
链接: arXiv
论文目标
目前的任意形状文本检测工作尽管取得了不错的结果,但是仍然存在两个问题,一个是基于分割的文本检测方案需要复杂的后处理流程,从分割图中提取文本边框坐标,而且很难区分间距比较小的文本目标,。另一个问题是,基于分割的方法很容易受到图像中的噪声等影响,特别是由于文本没有比较完整的轮廓,基于轮廓的检测方式效果比较差。
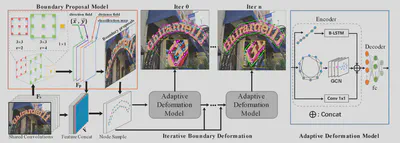
在文中提出了一个端到端的文本检测模型,包括BPN(Boundary Proposal Network)和一个迭代的变形模型,可以不经过任何后处理就直接生成任意形状文本的边界位置。
相关工作
基于回归的方法通常计算生成的anchor或者当前像素到图文边界框的距离,很难识别任意形状的文本或者是宽高比较大的文本。基于联通成分的方法通常找到文本中的单独成分然后连接起来,需要复杂的后处理流程。基于分割的方法通常通过文本边界来进行像素级预测,但是难以区分比较近的多个对象。基于轮廓点的方法学习寻找文本对象的轮廓点,相比分割的方法具有更高的效率和准确度。
本文方法
模型主要结构如图,包含三个部分,最前方的特征提取(Shared Convolution)、边界建议网络(Boundary Proposal Network,BPN)和自适应边界修正模型(Adaptive Deformation Model)。
特征提取模块如图,是基于ResNet-50的类似FPN/U-Net的结构。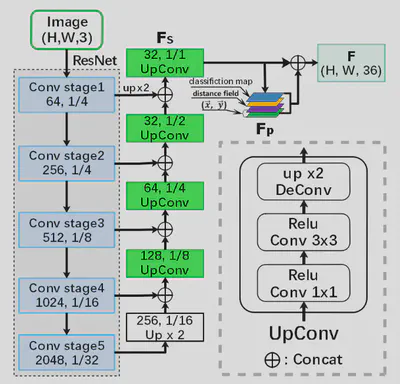
在BPN中,输出为四个通道:text/non-text classification、distance field和direction field。其中距离图和方向图表示当前点距离边界框上最近的点的距离和方向。通过距离和方向可以从当前点的坐标导出边界框的坐标。相关的监督数据如下图所示。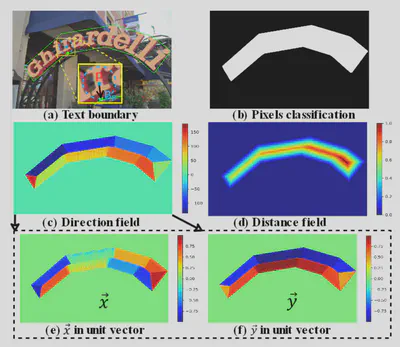
BPN输出的四个通道数据与特征提取模块输出的特征相拼接。从中选择N个点,每个点特征长度为C,得到了NxC的矩阵输入修正模型。
在自适应修正模型中,分为编码器和解码器两部分。编码器通过三个并行的模块:RNN(使用Bi-LSTM),GCN(将每个点与相近的四个点相连接),CNN(1x1的卷积)之后再连接起来进入解码器。解码器使用全连接层输出正确结果距离当前结果的偏置值用于更新。
在训练修正模型时采用迭代的方式。整体的损失函数如下。 $$\begin{aligned} L =& L_{BP} + \lambda\frac{L_{BD}}{1 + e^{(i-eps) / eps}} \\ L_{BP} =& L_{cls} + \alpha \times L_D + L_V \\ L_V =& \sum w(p)||V_p - \hat{V}_p||_2 + \frac{1}{T}\sum(1 - cos(V_p \hat{V}_p)) \\ w(p) =& \frac{1}{\sqrt{GT_p}} \\ L_{BD} =& \frac{1}{T}\sum L_{(p,p')} \\ L_{(p,p')} =& \min\limits_{j \in [0,1,2,...N-1]}\sum\limits_{i=0}^{N-1} smooth_{L1} (p_i, p'_{(i+j)\% N}) \\ \end{aligned}$$
结果分析
实验在Total-Text、CTW-1500、MSRA-TD500、SynthText、ICDAR2017-MLT数据集上训练。
经过Ablation Study可以证明提出的Adaptive Deformation Model可以提高模型的性能。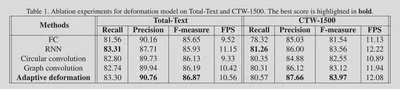
经过实验,每个目标的控制点(轮廓点)数量为20、迭代修正次数为3时效果较好,综合距离图、方向图的效果比只使用分类图要好,FPN分辨率选择1/2或者1/4均能达到比较好的效果。
在常见数据集上实验证明达到了SOTA。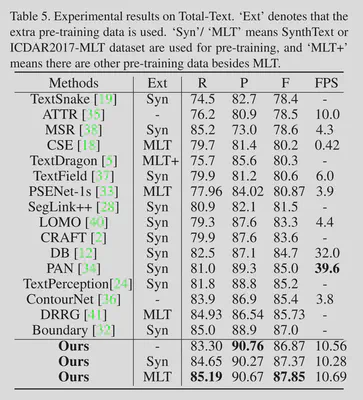
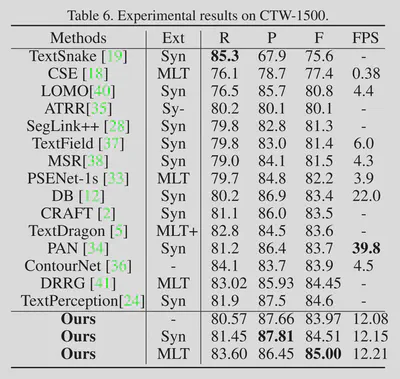
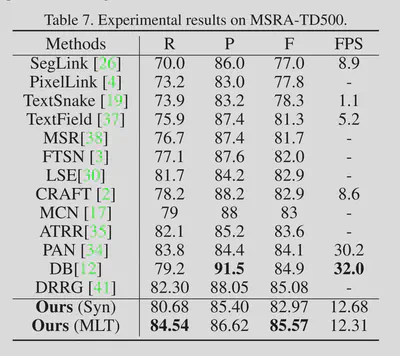
总结
- 使用图网络和RNN作为修正模型对粗检测结果进行修正。
- 提出BPN,根据模型提取的特征输出边界框的粗检测结果。