【论文】Class-wise Dynamic Graph Convolution for Semantic Segmentation
论文题目:Class-wise Dynamic Graph Convolution for Semantic Segmentation
作者:Hanzhe Hu, Deyi Ji, Weihao Gan, Shuai Bai, Wei Wu, and Junjie Yan
会议/时间:ECCV2020
链接: Springer
论文目标
使用GCN的方式来增强图像分割模型的感受野,提取丰富的上下文信息。使用由粗到细的方式,在GR中只引入同类型像素的特征进行增强。
使用膨胀卷积等方式增大感受野不适用于像素级预测的密集任务,会出现信息丢失。因此可以使用GCN或者基于Attention 注意力机制的方法。但是使用注意力的算法往往使用全部像素特征聚合进行分类,很难得到具有判别力的像素特征。因此采用了只关注同类别像素特征和关注难正例、难反例的方式加强特征提取。同时也进一步减小全连接图带来的计算成本。
相关工作
语义分割相关的工作包括UNet、SegNet、RefineNet、PSPNet、Deeplab等。都是采用了增加层数、膨胀卷积的方式增加感受野。
在聚合上下文信息方面的工作包括DeepLab 系列、DANet、PSPNet、Non-Local Block等,包括使用Multi-Grid或者Attention 注意力机制的方式增强感受野。
在Graph Reasoning 图推理相关的工作包括DeepLab引入的CRF 条件随机场、GloRe等。基本都是建立全连接图进行处理和分析。综合考虑了所有像素的特征。
本文方法
整体结构如下,首先进行粗检测结果,得到$M$个类别的Mask图,接着将原本的图像特征重复$M$次分别用对应的Mask进行掩码处理,得到类别有关的特征。接着进行图卷积。
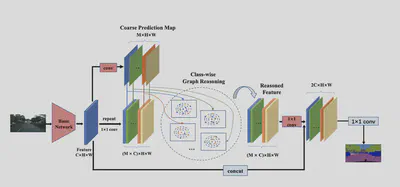
图卷积的关键是建立邻接矩阵,这里关键的两点设计为相似度邻接矩阵和难例筛选。
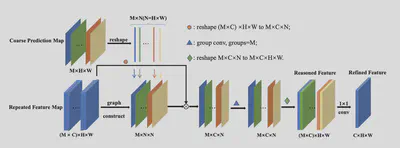
在构建图的时候,一种方法(Basic-GCN)使用相似度和Softmax操作得到行归一化之后的邻接矩阵。 $$\begin{aligned} F(x_i, x_j) &= \phi(x_i)^T \phi'(x_j) \\ A_{ij} &= \frac{exp(F(x_i, x_j))}{\sum_j exp(F(x_i, x_j))} \end{aligned}$$
另一种方法(Dynamic Sampling GCN)是使用难例筛选,令 $C$ 为预测得到的Mask,$G$ 为Ground Truth。可以得到 $Easy Positive = C \cap G$,$HardNegative = C - C\cap G$,$Hard Positive = G - C \cap G$。
于是采样点为 $$\begin{aligned} Sampled &= C-C\cap G + G - C\cap G + ratio \cdot C\cap G\\ &= C\cup G - (1-ratio)\cdot C \cap G \end{aligned}$$ 这里在训练的时候使用Ground Truth进行难例筛选,在推断的时候使用全部预测mask进行推断。
在GCN的部分使用M组参数分别进行卷积。最后通过1x1的卷积得到与原本特征形式相同的特征。
训练的损失函数包括粗检测结果和最终检测结果的监督。同时在Backbone中间也加入了辅助损失加快收敛。
结果分析
ablation study做的比较多。

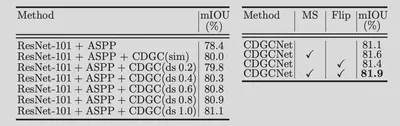

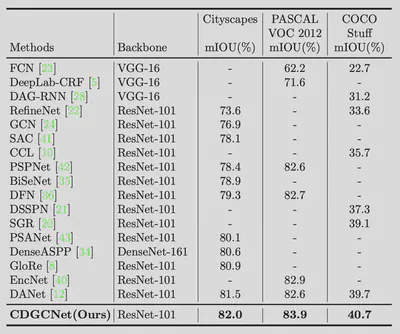
最后比了一下SOTA。
总结
在图卷积的部分就设计了难例筛选,而不是像OHEM那样在最后的分割图上做mining。
从coarse-to-fine的思路出发。
个人觉得有点类似OCRNet。