【论文】A Discriminative Feature Learning Approach for Deep Face Recognition
论文题目:A Discriminative Feature Learning Approach for Deep Face Recognition
作者:Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao
会议/时间:ECCV2016
链接:原文链接
论文目标
之前的工作中仅仅使用Softmax loss作为模型的监督信号,学到的模型具有一定判别能力(Separable),本文通过介绍一种新的Centor Loss作为监督信号进行学习,使模型学到更具有判别能力(Discriminative)的特征。Centor Loss可以学习到一类特征的分类中心并减小类内距离,从而更具有更强的判别能力。
相关工作
传统的度量学习(Metric Learning)中,由于识别样本在训练集中出现过,使用Softmax可以起到比较好的学习效果。但是在面识别任务中,很难预先搜集到所有可能的实体的数据用于学习,因此对于泛化能力的要求更高。这就要求学习到的特征具有更小的类内距离和更大的类间距离。
使用contrastive loss或者triplet loss对于pair/triplet的取样要求比较高,使用精心设计的取样方法可以在一定程度上避免,但是引入了更高的计算复杂度。
本文思路/解决方案
首先定义了centor loss函数 $$\mathcal{L}_c = \frac{1}{2}\sum\limits_{i=1}^{m}||\mathbb{x}_i-\mathbb{c}_{y_i}||^2_2$$ 其中 $\mathbb{c}$表示对应的类的中心。
直观的想法是在每一轮学习结束后将所有同类别数据的特征求均值,但是在大规模数据库中难以实现,因此采用每一批中同类别的数据的特征求均值用于类中心的更新。即令 $$\Delta\mathbb{c}_j = \frac{\sum\limits_{i=1}^{m}\delta(y_i=j)(\mathbb{c}_j - \mathbb{x}_i)}{1+\sum\limits_{i=1}^{m}\delta(y_j = j)}$$
其中 $\delta(condition) = condition\ is\ true ? 1: 0$,同时引入一个超参数$\alpha$作为类的中心更新时的“学习率”。
完整的loss function为
$$\mathcal{L} = \mathcal{L}_s + \lambda\mathcal{L}_c$$,其中$\lambda$为权重系数。
网络结构如下:可以看到引入了跨层连接和Joint Supervision Signal。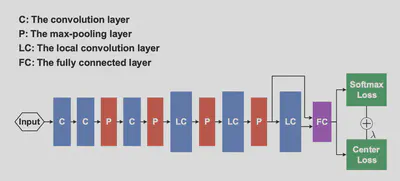
训练结果如下:可以看到在引入了Center Loss之后,类间距离显著减小,判别能力增强。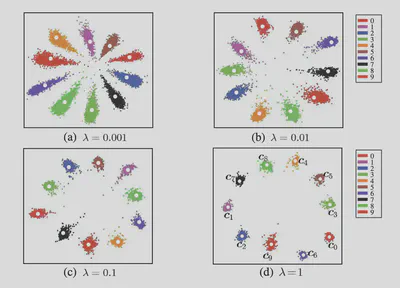
结果
可以发现 $\lambda=0$时的学习效果较差,当 $\lambda$太大时学习效果也会下降,测试得到的参数为$\lambda=0.03$。
可以发现$\alpha$的取值对结果影响不大(不为零时),测试得到的参数为$\alpha=0.5$。
最终实现的模型在小数据库训练,LFW达到了99.28%泛化准确率,YTF达到了94.9%的泛化准确率。
在MegaFace数据库上测试的结果中,本文的模型均达到了更好的性能。
总结
- 提出了Center Loss,使用Center Loss结合Softmax Loss实现具有判别力的模型学习。
- 使用了跨层连接的模型结构。
- 使用Joint Supervision Signal,合理选择权重超参数。