【论文】ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection
论文题目:ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection
作者:Yuxin Wang, Hongtao Xie, Zhengjun Zha, Mengting Xing, Zilong Fu, Yongdong Zhang
会议/时间:CVPR2020
链接: arXiv
论文目标
目前的图像文本检测算法常常会将一些纹理信息识别为文本,得到假正例,而且图像文本常常具有多种尺度大小和形状,难以识别。 在论文中提出了一种模型,通过引入自适应区域建议网络和正交的纹理敏感模块来解决上述问题。前者是一种区域大小无关的RPN网络,使用IoU监督,后者可以从正交的两个方向上检测纹理信息,有效避免假正例。模型检测结果为目标的若干个轮廓点,可以通过进一步后处理得到多边形边界框。
相关工作
近年来图像文本检测算法对于假正例的问题有多种解决思路:SPCNET中使用了语义特征来修正边界框,或者也可以使用置信度等修正边界框。
对于图像尺度多变的问题,MSR使用了多尺度网络结构、DSRN提出了双向多尺度关系网络等。
在传统文本检测中常用的算法包括连通域分析和滑窗处理。在深度模型中常用的思路包括基于边界框回归的思路和基于语义的思路。前者包括EAST、DDR、LOMO等首先需要使用Anchor-Based或者Anchor-Free的思路生成边界框。后者需要对分割图进行后处理。
本文方法
模型包括两个部分,前半部分Adaptive-RPN生成文本所在区域,然后使用LOTM进行两个方向的处理得到文本轮廓点。
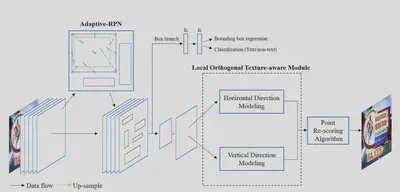
在Adaptive-RPN中,传统方法是使用生成四个值 $\{\Delta x, \Delta y, \Delta w, \Delta h\}$去优化得到矩形区域,使用$l_1\ Loss$监督。但是这样的方式对于区域的大小比较敏感。
本文中一方面使用$N$个点来表示$RoI$,其中一个点表示区域中心,剩下$N-1$个点表示区域的边框,根据这$N$个点的最边界点得到$RoI$。另一方面使用$IoU\ Loss$来监督这个$N$个点的回归,对尺度不敏感。计算最边界点的方式如下: $$\begin{aligned} Proposal = & \{x_{tl}, y_{tl}, x_{rb}, y_{rb}\} \\ = & \{\min\{x_r\}_{r=1}^n, \min\{y_r\}_{r=1}^n, \\ \ & \ \max\{x_r\}_{r=1}^n, \max\{y_r\}_{r=1}^n\} \end{aligned}$$
在获得文本边界点的时候,使用了相互正交的两个方向上的特征分别得到轮廓点热力图。文中假设对于一个文字在两个方向上都具有明显的特征,但是其他无意义的纹理通常只在一个方向上具有比较明显的特征,因此可以通过两个方向上的分别处理区分开。
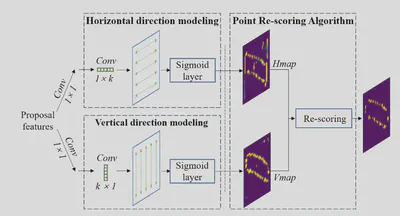
接着在后处理算法中将两个轮廓点热力图合并起来得到文本轮廓点。其算法如下,首先分别进行NMS处理减少多余的点,然后将两个方向上都都具有较高置信度的点作为输出得到轮廓点。最终通过Alpha-Shape Algorithm得到多边形边界框。

需要注意在生成监督的时候,对于两个方向上的轮廓点都使用相同的监督,即通过原始多边形边界框生成的宽度不低于2个像素的边框(这里是我的理解,原文如下)。
we use
distance_transform_edtin Scipy to obtain the two-points wide edge.
结果分析
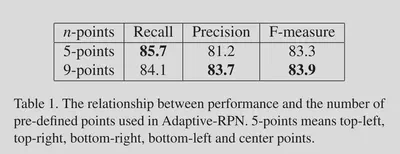
对于Adap-RPN中表示RoI的点的数量的实验。
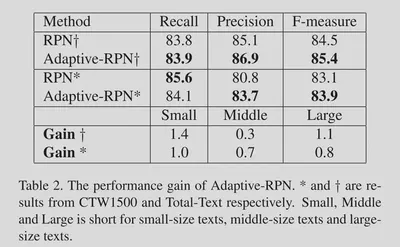
对于Adap_RPN的有效性的实验。
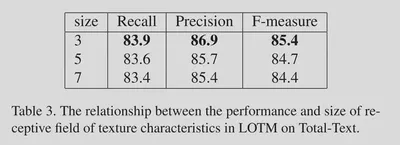
对于LOTM中$1\*N$和$N\*1$卷积长度的实验。
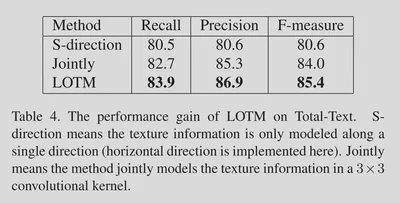
对于LOTM的两方向特征融合效果的实验。
总结
在三个任务上(弯曲文本:Total-Text,长弯曲文本:CTW1500,多方向文本:ICDAR2015)均相对SOTA有一定的提升。可以看到本文方法有效减少了假正例的出现。