【论文】Character Region Awareness for Text Detection
论文题目:Character Region Awareness for Text Detection
作者:Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, and Hwalsuk Lee
会议/时间:CVPR2019
链接:https://arxiv.org/pdf/1904.01941.pdf
论文目标
今年来使用深度神经网络实现的文本检测得到许多关注,但是过去的文本检测工作大多使用边界框框选每一个词,存在一定的缺陷,例如在单词非常长或者扭曲畸形的情况下效果不好,本文提出了一种基于检测单个字符的文本检测模型,通过检测连续的字符实现自下而上的单词检测。由于成本非常高,现有的文本检测数据库并没有提供字符级的标注,文中使用弱监督学习方法,可以在单词级标注的数据集上训练字符级模型。
相关工作
很多的文本检测模型(即regression-based text detectors),使用了目标检测模型中常用的边框回归思路。尽管取得了比较好的效果,但是不能应对实际场景下的各种形状的文字。一些文本检测模型(segmentation-based text detectors),在像素级分割和检测文本区域。还有一些端到端的文本检测工具将文本检测和识别任务结合在一起,可以避免一些背景中的图形的影响,提高检测效果。大多数的文本检测是以单词为识别单位,但是在标注和划分时很难确定,造成效果较差。
本文思路/解决方案
本文构建卷积神经网络,从图像中学习得到字符(region score)和字符之间的连接关系(affinity score),从而从数据中检测单词和句子。
模型使用添加了BatchNormal的VGG-16作为基本结构,通过添加解码器和短路连接构建了类似U-Net的模型结构,最终输出2通道的特征图。
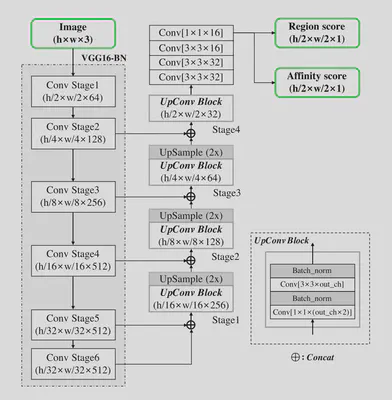
模型输出的特征图分别表示字符和字符之间的连接关系。region score表示当前像素为一个字符中心点的概率,affnity score表示当前像素为两个字符中间点的概率。本文使用了高斯热力图来表示字符的位置,相比使用几何形状框选,更容易表示各种形状的字符。
数据标注的生成方式 如下,分别对每一个字符使用四边形框选,在每个框中选择上下两个三角的中心点生成新的四边形,将二维高斯热图变换填充进去得到。
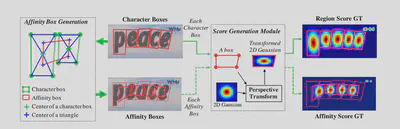
在训练过程中,由于实际的数据集只有单词级或者句子级的标注,首先使用合成的样本训练得到一个临时的模型,然后将实际数据集中的单词或者句子裁剪出来通过模型得到单词边界框,与原数据预测的结果相比计算置信度。一种可行的方法是使用字符框的个数与单词长度相比较得到置信度,作为计算目标函数时的像素权重。即
$$L = \sum\limits_{p} S_c(p)\cdot(||S_r(p) - S_r^*(p)||^2_2+||S_a(p) - S_a^*(p)||^2_2)$$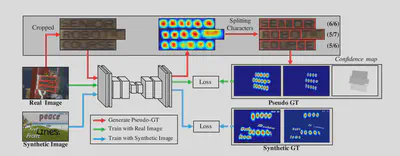
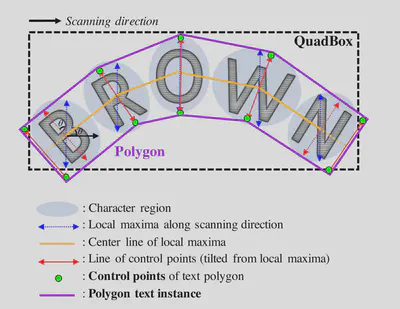
最后在预测时需要进行相应的后处理,例如使用矩形框将检测到的文本从原数据裁剪出来包括如下操作:分别设置阈值将特征图转为二值,使用连通区域标记技术从二值图中框选单词,最后选择一个矩形框将上述连通区域框选出来1。或者使用多边形折线框框选:每个字符使用相同长度的竖线表示,竖线的中点连线得到单词中线,上述竖线转至与中线垂直,以端点为多边形的顶点绘制中线的平行线。
结果
在选择的六个数据集上,经过训练和测试,都实现了超过SOTA的效果。可以证明使用字符级的检测效果比较好。
总结
提出了一种基于检测单字符从而实现文本检测的方法,针对数据标注比较少的情况引入了弱监督的训练方式,取得了比较好的结果。
模型通过检测字符而不是单词,在感受野比较小的情况下具有较好的鲁棒性,但是只能针对字符相分离的语言,不能处理孟加拉语、阿拉伯语等语言。模型中只有文本检测没有文本识别,与端到端的模型相比性能受限,但是在多个数据集上都取得了非常好的结果,证明泛化能力比较强。
可以使用opencv中提供的connectedComponents函数和minAreaRect函数等实现。 ↩︎