【论文】Real-time Scene Text Detection with Differentiable Binarization
论文题目:Real-time Scene Text Detection with Differentiable Binarization
作者:Minghui Liao, Zhaoyi Wan, Cong Yao, Kai Chen, Xiang Bai
会议/时间:AAAI2020
链接:https://arxiv.org/pdf/1911.08947.pdf
论文目标
基于目标分割的文本检测系统通常能取得比较好的结果,尤其是在检测形状比较多变的文本目标的时候,但是基于分割的系统通常需要设计后处理算法,对模型输出的概率图加以处理得到文本区域的位置。为此本文设计了Differentiable Binarization模块,使得模型同时输出分割图和阈值,使用模型输出的阈值对分割图进行二值化可以得到比较好的结果。
相关工作
近年来图像文本检测的算法主要分为两类,即基于回归的和基于分割的。前者包括TextBoxes、SSD、EAST、SegLink等,后者包括Mask TextSpotter、PSENet等。同时有一些快速文本检测算法,旨在在不损失精确度的情况下提高预测的速度。例如在SSD的基础上发展了TextBoxes++和RRD等,在PVANet基础上发展EAST等。
本文思路/解决方案
整体使用特征金字塔结构,不同尺度的特征图融合得到特征F,在此基础上得到预测图和阈值图,利用阈值图T对预测图P二值化,得到二值化的图像B,最终得到检测结果。在训练过程中预测图和二值化图使用相同的目标监督,在预测的时候可以通过预测图或者二值化图中的任意一个得到目标检测结果。
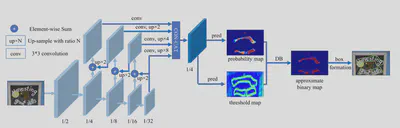
为了便于梯度传播,这里使用了可微的二值化函数代替标准的二值化。 $$\begin{align} \hat{B}_{i,j} = \frac{1}{1+e^{-k(P_{i,j}-T_{i,j})}} \end{align}$$ 同时在文章中使用的ResNet-18和ResNet-50中采用了可变形卷积取代原本的卷积操作,经实验有一定的性能提升。
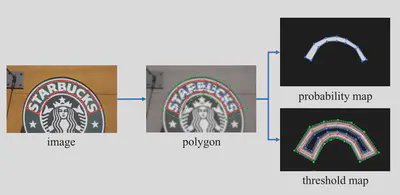
在生成标签时,使用Vatti算法,将多边形框收缩得到预测图的标签。同时将多边形框收缩和膨胀,其中的区域作为阈值图的区域,阈值图的取值由距离原多边形框的距离确定。
在计算loss的时候,使用 Binary Cross-Entropy(BCE)作为预测图和二值化图的损失函数,使用L1距离作为阈值图的损失函数。其中$R_d$是膨胀后的边界框内部的像素,$S_l$是用于计算的数据集合。 $$\begin{align} L &= L_s+\alpha L_b+\beta L_t \\ L_s = L_b &= \sum\limits_{i \in S_l}y_i\log x_i + (1-y_i)\log(1-x_i) \\ L_t &= \sum\limits_{i\in R_d}|y_i^* - x_i^*| \end{align}$$
结果
使用了可变形卷积和DB模块之后,模型在CTW1500和MSRA-TD500上的性能均有所提升。为阈值图添加监督之后性能也有所提升。在卷曲文本、多语言文本、多朝向文本上的效果均相比之前的模型有所提升。
总结
引入了DB模块,通过二值化阈值的预测提升检测的结果,同时使用了比较精简的模型,具有较快的处理速度。