【论文】DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement
论文题目:DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement
作者:Mohamed Ali Souibgui and Yousri Kessentini
会议/时间:arXiv
链接: arXiv
论文目标
文档图像中通常会拥有比较多的退化(Degradation),因此在使用OCR系统处理文档图像的时候效果比较差,论文通过生成对抗网络(GAN)实现了一个文本增强模型,在例如去除模糊、去除污渍、去除水印、二值化等多种文档增强人物上具有较好的效果。
在通常的文档去除污渍、去除水印等任务中,对于这些水印/退化条件缺少先验知识,特别是污渍将字符完全覆盖的情况。因此很难用传统的方法去除。近年来生成模型在应对缺失数据、多模态任务中取得非常好的结果。因此在论文中,首次在文档增强任务中使用了生成对抗网络来解决二值化和去除水印的任务。而且论文中还提出了密集水印/印章移除任务。
相关工作
文档图像修复和二值化任务旨在将文本和背景/污渍相区分,传统方法中大多使用设置阈值的方式,包括全局阈值、局部阈值搜索等方式,但是传统方法对于文档状态非常敏感,不够通用。在使用深度神经网络的方法中,整体思路类似图像分割,输出像素级的预测结果,判断当前像素为文本前景还是污渍背景。在论文中所使用的文档增强任务将污渍背景预测为正确的颜色/灰度,而不是设置为0。
在水印移除任务中,目标是将水印前景与文本背景相分离,多出现在自然图像处理(Natural Image Processing)任务中,此前常见的做法首先使用通用的目标检测算法检测水印/印章的位置然后再移除。
目前生成对抗网络已经广泛应用于图像到图像的转换任务中,例如语义分割、图像超分辨率等。其中conditional GANs常被应用在一些与文档增强相似的任务中。例如CycleGAN、pix2pix-HD等模型。
本文方法
首先将文档增强任务定义为图像到图像的转换任务。即给定原始图像生成对应的干净的图像。在最简单的GAN网络中,给定随机抽样$z$,生成图像$y$。在conditional GAN网络中,给定了一个另外的输入参数$x$,生成器依据输入$x$和随机向量$z$生成$y$,即 $G\_{\varphi\_G}:\{x,z\}\to y$,判别器依据输入$x$判别$y$的真伪,即 $D\_{\varphi\_D}: \{x, y\}\to P(real)$。
在最简单的conditional GAN网络中,给定输入为$I^W$,Ground Truth为 $I^{GT}$,模型的对抗损失如下。即最小化判别器分类的损失。 $$\begin{aligned} L_{GAN}(\varphi_G, \varphi_D) &= \mathbb{E}_{I^W, I^{GT}}\log[D_{\varphi_D}(I^W, I^{GT})] \\ &+ \mathbb{E}_{I_W} \log[1 - D_{\varphi_D}(I^W, G_{\varphi_G}(I^W))] \end{aligned}$$
在论文中,为了加速模型的训练,添加了额外的辅助损失指导模型的训练。公式如下。(添加了生成器输出结果和Ground Truth之间的交叉熵损失?)
$$\begin{aligned} L_{log}(\varphi_G) &= \mathbb{E}_{I^{GT}, I^W}[-(I^{GT}\log(G_{\varphi_G}(I^W)) \\ &+ ((1-I^{GT})\log(1-G_{\varphi_G}(I^W))))] \\ L_{net}(\varphi_G, \varphi_D) &= \min_{\varphi_G}\max_{\varphi_D}L_{GAN}(\varphi_G, \varphi_D) + \lambda L_{log}(\varphi_G) \end{aligned}$$模型整体结构如下。
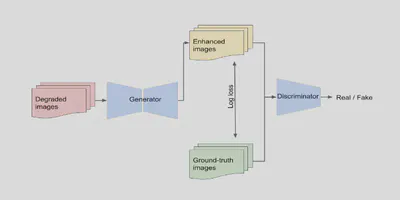
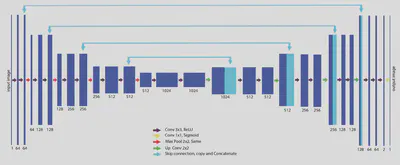
对于生成器,使用了基于U-Net的结构,添加旁路链接可以减少信息的丢失,也可以使模型学习更加高级的特征。
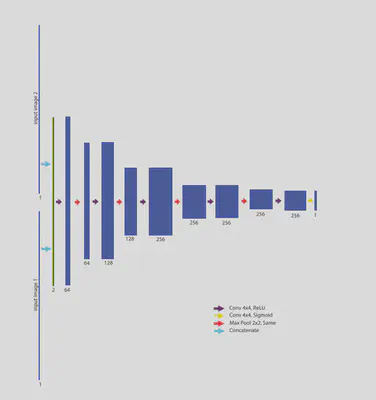
对于判别器,使用简单的多层卷积的结构。在输入层将生成器输出的图像与Ground Truth通过Concatenate相连接。
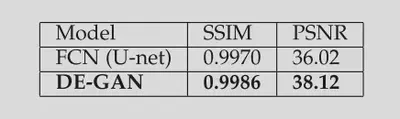
结果分析
在文档清洁和二值化任务中,损失函数中的$\lambda$设置为100。与最简单的U-Net相比,模型性能有所提升。说明使用对抗训练可以增强模型的性能。
在DIBCO2013上与现有模型相比达到了SOTA的效果。
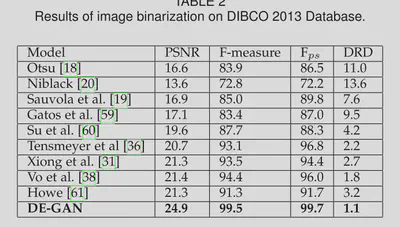
在水印和印章移除任务中,损失函数中的$\lambda$设置为500。与现有模型相比达到了SOTA的效果。
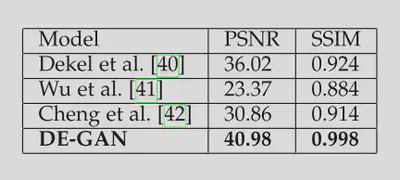
除此之外,还在文档去模糊等任务上和下游的OCR任务上做了测试,均取得了非常好的效果。
总结
论文中首次提出了使用GAN解决文本增强任务。文中提出的DE-GAN可以认为是pix2pix模型的升级版,通过修改生成器和辅助损失函数提升了模型性能,在很多文档增强任务中都取得了非常好的效果。