【论文】Feature Extraction for Visual Speaker Authentication against Computer-Generated Video Attacks
论文题目:Feature Extraction for Visual Speaker Authentication against Computer-Generated Video Attacks
作者:Jun Ma, Shilin Wang, Senior Member, IEEE, Aixin Zhang and Alan Wee-Chung Liew
会议/时间:IEEE ICIP 2020
论文目标
使用唇语特征进行身份认证具有一定的活体检测能力,但是容易受到使用DeepFake等技术构建的视频攻击,因此构建一个神经网络从视频中提取动态的说话习惯信息,同时尽量减少唇语特征身份认证对于唇部静态特征的依赖。
相关工作
之前的工作中他人使用了唇部的图像和运动特征、纹理描述符等方式实现了比较不错的结果。作者所在 团队之前的工作中使用3D残差单元实现了唇部动态和静态特征的提取。
近来使用DeepFake换脸技术可以很容易伪造讲话视频,甚至可以在单照片的数据集上实现。使用唇部特征的认证系统由于过多依赖静态特征,受到一定的威胁。
本文提出的网络结构的基础包括frame difference、self-attention、non-local neural network1等。
本文思路/解决方案
构建了一个深度神经网络结构提取用户唇部特征用于认证。包括两个模块:Difference block(Diff-block)和Dynamic Response block(DR-block)两者相互补用于提取用户动态讲话特征信息。
Diff-block
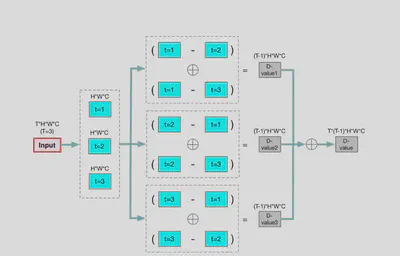
给定长度为T帧的视频,通过计算每一帧图像与其他T-1帧图像的相关性来消除静态特征。
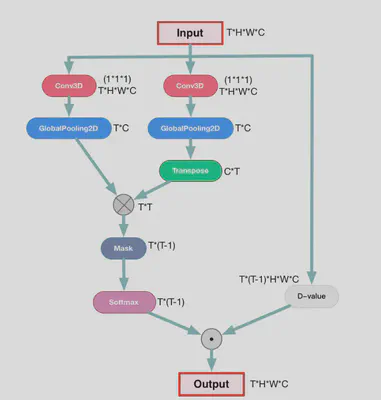
其中$\theta(x_t)$和$\varphi(x_j)$为输入数据分别经由两组不同的Conv+Pool之后得到的,经过转置和相乘得到 $T\*T$ 形状的张量,表示两帧数据之间的相关性。将原数据经过 D-value操作 之后得到每一帧与其他帧的差值,并按照上述操作得到的相关性矩阵加权求和得到最终的输出。
DR-block
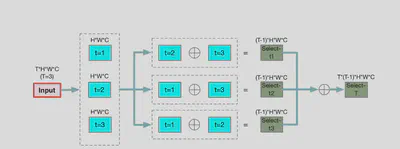
用于提取像素级的全局动态信息,通过计算同一空间位置上的像素在不同时间位置的差异实现。
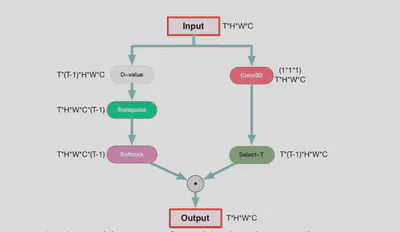
其中$g(p(t,h,w,c),p(j,h,w,c))$计算相同空间位置不同时间位置的像素差异。原数据首先经过 D_value操作 和softmax后得到了像素值的差异。原数据经过 Select-T操作 提取到特征,按照上述操作得到的差异矩阵加权求和得到了最终的输出。
DEA_Net

结果
使用GRID数据集用于模型的评估和测试,使用Faceswap工具生成攻击视频。经过测试,本文提出的模型与SOTA模型相比拥有更低的FAR和HTER,取得了比较好的结果。可以证明Diff-block和DR-block结合能够有效的消除数据中的静态特征,更好的对抗换脸攻击。
总结
- 提出了两个网络单元用于消除数据中的静态特征,提取动态特征用于识别和认证。
- 使用了non-local neural network的结构,增大了感知域,使得浅层网络可以学习到更多的全局信息。
-
X.L. Wang, R. Girshick, A. Gupta, and K.M. He, “Non-local neural networks,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794-7803, 2018. ↩︎