【论文】EAST: An Efficient and Accurate Scene Text Detector
论文题目:EAST: An Efficient and Accurate Scene Text Detector
作者:Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang
会议/时间:CVPR2017
链接:https://arxiv.org/abs/1704.03155v2
论文目标
传统的文字检测模型尽管可以取得不错的效果,但是往往由多个阶段和结构组成,这样复杂的结构往往会影响到整体的性能,因此本文的作者设计了一种简单快速的pipeline,可以从给定图像中直接检测到文本的位置。通过使用一个简单的神经网络而不是多个模块组合的方式加快了处理的速度,简化了模型的复杂度。
相关工作
常规的处理方法依赖于人工设计的特征,例如SWT和MSER等模型通过边缘检测等方式。但是这些依赖人工设计特征的算法在处理一些有挑战性的场景时效果比较差,例如低分辨率或者出现失真的情况下。
相比之下,基于深度神经网络的文本检测算法由于能取得更好的效果,逐渐成为主流,包括使用CNN对文本检测的结果进行筛选或者使用FCN生成热力图/分割图对原始图像处理得到检测结果。但是多数基于深度神经网络的模型由多个阶段组成,结构比较复杂性能也比较差。
本文思路/解决方案
本文设计了一个基于FCN的神经网络,且完整的模型只有两个阶段,省去了冗余的中间处理阶段,即神经网络得到预测的文本框,再通过非极大值抑制得到最终的预测结果。
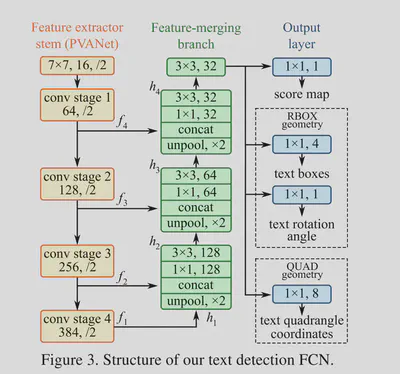
基于FCN的网络结构设计如下,通过神经网络直接得到了三类型的输出:Score Map、Rotated Box、Quadrangle。其中的score map为置信度,置信度超过给定阈值的预测框通过NMS得到最终的输出。通过使用U-Net可以融合不同尺度的特征,有助于检测不同大小的文本目标。
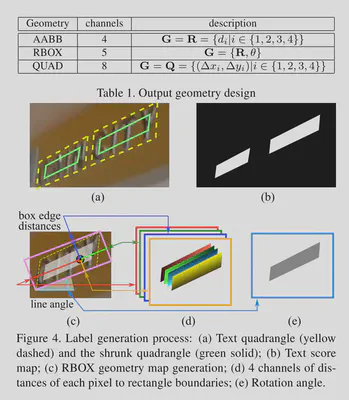
在生成GT时,将原本的四边形缩小到0.7倍并二值化可以得到Score Map,对于没有RBOX标注的数据,首先根据QUAD创建一个最小矩形,再计算每个点到四个边界的距离得到RBOX标注。
对于损失函数的计算,采用了Score Map损失和Geometry损失的加权平均值。由于在自然场景下的图像中,检测目标与背景占据的面积不均衡,在计算Loss的时候会受到影响,为了不引入额外的处理流程,计算Score Map损失时使用了class-balanced cross-entropy,可以比较好的解决正反例不均衡的情况。
$$\begin{aligned} L_s =&\; \operatorname{balances-xent}(\mathbf{\hat{Y}}, \mathbf{Y^*}) \\ =& -\beta\mathbf{Y^*}\log\mathbf{\hat{Y}}-(1-\beta)(1-\mathbf{Y^*})\log(1-\mathbf{\hat{Y}}) \\ \beta =&\; 1 - \frac{\sum_{y^*\in\mathbf{Y^*}}y^*}{|\mathbf{Y^*}|} \end{aligned}$$对于Geometry输出的损失函数,在RBOX的情形中,对于AABB部分使用IOU损失,对于倾斜角的部分使用余弦函数计算损失。 $$\begin{aligned} L_{AABB} =&\; -\log\operatorname{IoU}(\mathbf{\hat{R}},\mathbf{R^*}) \\ =&\;-\log\frac{|\mathbf{\hat{R}}\cap\mathbf{R^*}|}{|\mathbf{\hat{R}}\cup\mathbf{R^*}|} \\ L_\theta(\hat{\theta},\theta^*) =&\;1 - \operatorname{cos}(\hat{\theta} - \theta^*) \\ L_g =&\;L_{AABB} + \lambda_\theta L_\theta \end{aligned}$$ 在QUAD的情形中,使用增加了正则项的smoothed-L1损失计算。 $$\begin{aligned} L_g =&\; L_{QUAD}(\mathbf{\hat{Q}},\mathbf{Q^*}) \\ =&\;\min\limits_{\mathbf{\tilde{Q}} \in P_{\mathbf{Q^*}}}\sum\limits_{c_i \in C_{\mathbf{Q}} \\\tilde{c}_i\in C_{\mathbf{\tilde{Q}}}} \frac{\operatorname{smoothed_{L1}}(c_i - \tilde{c}_i)}{8 \times N_{\mathbf{Q^*}}} \\ N_{\mathbf{Q^*}} =&\;\min\limits_{i=1}^{4}D(p_i, p_{(i \operatorname{mod} 4)+1}) \end{aligned}$$
对于模型输出的结果,使用阈值筛选之后,再使用作者设计的一种基于合并候选框的NMS算法处理得到结果。

结果
在ICDAR2015、COCO-Text和MSRA-TD500三个数据集上进行测试。同时对于模型的骨架也使用了PVANET、PVANET2x和VGG16三种不同的结构进行测试(网络框架都在InageNet上预训练)。经测试模型在上述数据集上能取得超过SOTA的F值。在处理速度上也能达到比较高的FPS。
总结
本文提出的EAST模型,通过减少冗余的处理阶段,得到了简单快速的处理效果,通过FCN网络直接生成预测的结果(geometry map),结合NMS处理多余的候选框,可以得到比较好的效果。