【论文】Landmark-Guided Cross-Speaker Lip Reading with Mutual Information Regularization
论文题目:Landmark-Guided Cross-Speaker Lip Reading with Mutual Information Regularization
作者:Linzhi Wu, Xingyu Zhang, Yakun Zhang, Changyan Zheng, Tiejun Liu, Liang Xie, Ye Yan, Erwei Yin 单位:University of Electronic Science and Technology of China,
会议/时间:arxiv 2024, COLING 2024
链接: arxiv.
TL; DR
前端网络的修改主要两部分: 一方面用landmark提取关键点周围的3D特征 一方面用帧差的时序卷积提取动态特征。
后端网络添加了一个身份识别模块,做两阶段的对抗训练。 使得前端提取的特征偏向内容而不是身份。
论文目标
相关工作
本文方法
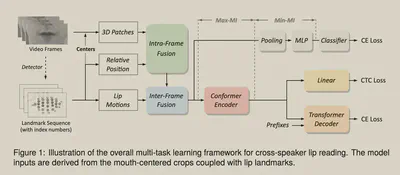
对抗训练的部分使用互信息的最大最小原则来训练。 最小化互信息的部分,使用CLUB作为互信息上界来最小化,
$$\begin{aligned} \mathcal I_{vCLUB}(X,Y) &:= \mathbb E_{p(X, Y)}\left[\log q_{\phi}(y|x)\right] - \mathbb E_{p(X)}\mathbb E_{p(Y)}\left[\log q_{\phi}(y|x)\right] \\ \mathcal L_{\min MI} &= \mathcal{I}_{vCLUB} (\mathbf h^{ID},\mathbf{H}^{L_b}) \end{aligned}$$最大化互信息的部分,使用JS距离作为互信息下界来最大化。 $$\begin{aligned} \hat{\mathcal{I}}^{(JSD)}_\theta (X,Y) &:= \mathbb{E}_{p(X,Y)}\left[−\log(1 + e^{-\mathcal F_\theta(x, y)})\right]− \mathbb{E}_{p(X)p(Y)}\left[\log(1 + e^{\mathcal F_\theta(x,y))}\right]\\ \mathcal L_{\max MI} &= -\hat{\mathcal{I}}^{(JSD)}_\theta (\mathbf H^{(0)},\mathbf{H}^{L_b}) \end{aligned}$$