【论文】Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
论文题目:Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
作者:Chengquan Zhang, Borong Liang, Zuming Huang, Mengyi En,Junyu Han,Errui Ding, Xinghao Ding
会议/时间:CVPR2019
链接: ieeexplore
论文目标
现有模型受到感受野的限制,很难实现对于长文本和弯曲文本的准确识别。论文中设计实现了一个LOMO网络,首先通过DR获得粗检测结果,再使用IRM迭代优化结果,最后使用SEM得到任意多边形的文本检测结果。
相关工作
目前的文本检测有三种思路:
- 基于Component,检测到文本部分然后通过后处理合并。例如CTPN、SegLink、WordSup等。
- 基于Detection,类似通用的目标检测。例如TextBoxes、RRD、RRPN、EAST等。
- 基于Segmentation,类似语义分割。例如TextSnake、PSENet等。
本文方法
整体的模型结构如下。基本的特征提取部分使用ResNet50和FPN实现。最终得到1/4大小的128通道的特征图。
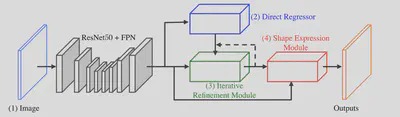
提取到的图像特征首先经过Direct Regressor得到粗检测结果。这里DR的设计与EAST基本相同,包括test/non-text分类结果和四个边界点的偏移值。在训练分类结果时使用了一种改进的Dice-Loss。其中的权重$w$被设置为与文本框的短边长度称反比。
$$L_{cls} = 1 - \frac{2 * sum(y * \hat{y} * w)}{sum(y*w) + sum(\hat{y} * w)}$$IRM的结构如下。首先根据DR的结果,从FPN的特征中使用ROI Transform提取特征,并使用卷积和Sigmoid激活得到四个通道的注意力图(分别为四个边角)。通过Reduce-Sum和卷积得到四个边角的偏移量。对DR的结果进行修正。
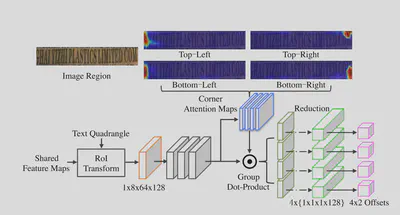
IRM部分的损失函数为使用Smoothed-L1来监督。
$$L_{irm} = \frac{1}{K*8}\sum\limits_{k=1}^{K}\sum\limits_{j=1}^{8}smooth_{L1}(c_k^j - \hat{c}_k^j)$$SEM的结构如下。根据IRM修正之后的结果,进一步得到多边形框的结果。除去上述检测框中的背景部分。首先同样是使用ROI Transform提取特征,然后经过两次上采样之后,再生成预测结果,包括文本区域、文本中心线(收缩后的文本区域)、边界偏置。
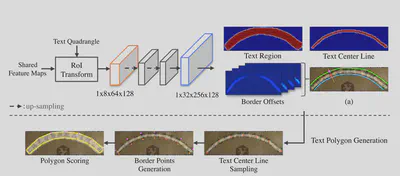
要想得到文本检测结果,需要首先在文本中心线上采样N个点,然后根据边界偏置得到文本行的上下边界上的控制点,相连接得到多边形框。
在训练时,首先使用生成数据对DR部分进行训练,然后才使用真实数据同时训练三个分支。为了防止训练时DR产生的错误结果影响另外两分支的训练,将DR结果中的50%随机替换为GT。在预测的时候DR的结果经过NMS之后再经过多次IRM,最后通过SEM得到结果。
结果分析
ablation study显示,IRM迭代次数增加可以提升模型性能,但是相应的处理时间增加,因此权衡之后设置为2。在IRM中,添加四个角点的注意力图也可以提升模型性能。
ablation study显示,添加SEM可以显著提升模型性能(7.17%)。对于SEM结果的处理中,采样点数量增加效果提升并逐渐收敛,因此选择为7。
在长文本数据集ICDAR2017-RCTW上的效果如下。
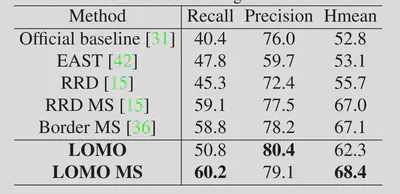
在弯曲文本数据集ICDAR2015上的效果如下。
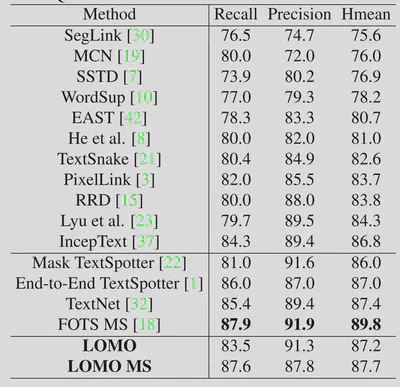
在多语言数据集ICDAR2017-MLT上的效果如下。
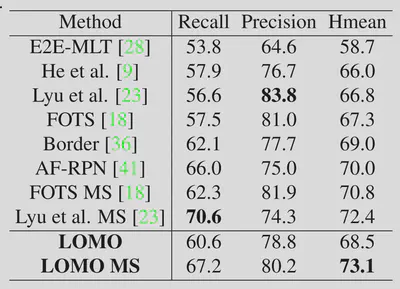
总结
设计了IRM在粗检测结果上精调。 设计了SEM实现文本框形状的优化,从四边形变换为任意形状。