【论文】An Effective Mixture-Of-Experts Approach For Code-Switching Speech Recognition Leveraging Encoder Disentanglement
论文题目:An Effective Mixture-Of-Experts Approach For Code-Switching Speech Recognition Leveraging Encoder Disentanglement
作者:Tzu-Ting Yang, Hsin-Wei Wang, Yi-Cheng Wang, Chi-Han Lin, and Berlin Chen 单位:National Taiwan Normal University
会议/时间:ICASSP 2024
链接: doi.
TL; DR
采用解耦结合MOE的方式来进行多语言的语音识别。
论文目标
ASR模型在单语言上有很好的性能,但是在Code-Switch场景下性能不好。
难点有两部分,一个是高质量数据集缺乏。一个是不同语言之间的差异。 不同的拼音语言之间差异较小,但是中文英文之间差异很大。造成模型会混淆。
相关工作
一种做法是LID,即language identification,使用语言分类预测头,判别当前位置是什么语言。 一种做法是双编码器,但是可能会损失不同语言上下文之间的关系。 因此常见做法是LAE,就是language-aware encoder,单一的编码器但是具有语言感知能力。
本文方法
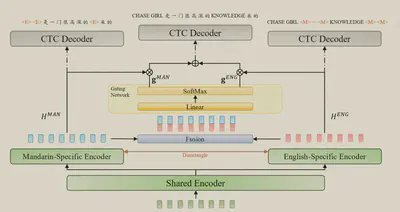
结构比较简单。
包含共享的编码器,提取完整的特征。语言特定编码器,提取特定语言特征。
语言特定编码器的监督是CTC损失,使用语言mask来指导。
MoE混合的监督也是CTC损失,使用完整的序列来监督。
完整的损失包含两部分,一部分是使用目标序列监督的CTC损失,还有一部分是解耦损失。 其中的解耦损失就是对应位置上的特征的Cosine距离。 即 $$\begin{aligned} L_{lang} &= \frac{1}{2}(L_{ZH} + L_{EN}) \\ L &= \frac{1}{2}(L_{Mix} + L_{Lang}) + \lambda L_{Disen} \\ L_{Disen} &= -\frac{1}{N}\sum_{i=1}^N \frac{1}{|s_i|}\sum_{j=1}^{|s_i|}CD(\mathbf h_{i, j}^{ZH}, \mathbf h_{i, j}^{EN})\\ CD(\mathbf h_{i, j}^{ZH}, \mathbf h_{i, j}^{EN}) &= 1 - \frac{\mathbf h_{i, j}^{ZH}\cdot \mathbf h_{i, j}^{EN}}{||\mathbf h_{i, j}^{ZH}||_2 ||\mathbf h_{i, j}^{EN}||_2} \end{aligned}$$
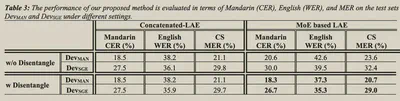
结果分析
在[[SEAME]]数据集上完成实验。
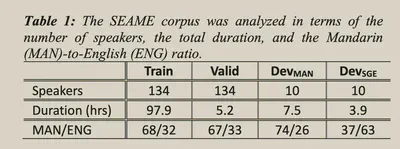
语言的预处理部分,中文字典包含2624个字,英文字典包含3000个BPE。
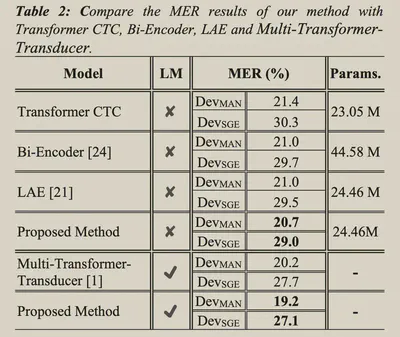
和简单Concatenate相比,使用MoE的方式在经过解耦之后有所提升。
如果不解耦直接使用MoE,会导致门控网络出现混淆。
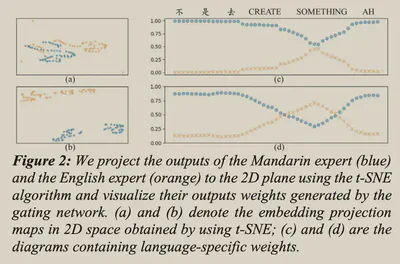
进一步可视化了Gating Network的输出。