【论文】MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
论文题目:MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
作者:Minghang He, Minghui Liao, Zhibo Yang, Humen Zhong, Jun Tang, Wenqing Cheng, Cong Yao, Yongpan Wang, Xiang Bai
会议/时间:CVPR 2021
链接: arXiv
论文目标
传统的文本检测算法对于长文本和小文本的检测效果比较差。为了解决长文本和小文本的检测问题,引入了新的NMS、IoU Loss和特征对齐模块。
例如在EAST中,由于使用分类输出作为NMS的权重,而且模型感受野比较小,很难获得足够的信息检测到长文本。
相关工作
现有的文本检测算法主要包括两种思路,自下而上和自上而下。其中前者主要是检测到文本中的部分元素,然后合并得到完整的检测结果,包括SegLink、TextSnake、CRAFT、PSENet等,由于需要复杂的后处理算法处理模型的输出结果,整体的处理效率受限制,而且后处理算法的效果也会影响到整体的结果。后者直接使用模型输出文本边框的检测结果,包括EAST、TextBoxes等。自上而下的又可以分为一阶段的和两阶段的,前者直接输出模型结果,后者包括Mask TextSpotter系列,使用类似Mask R-CNN的思路,首先使用RPN输出Proposal。
在LOMO模型中,使用了迭代优化模型,使用RoI Transform迭代优化模型结果,从而解决长文本的检测问题。
本文方法
模型整体结构如下,特征提取模块使用了基于ResNet50的FPN网络,上下两个分支来自EAST中的分类和位置预测图。
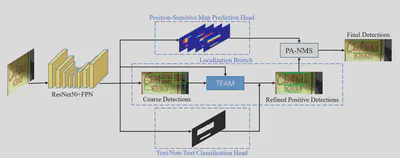
来自EAST的两个分支的监督与EAST相同。分类分支使用向内收缩后的文本框表示,位置预测图包括四个通道,表示当前位置距离文本框上下左右的距离。

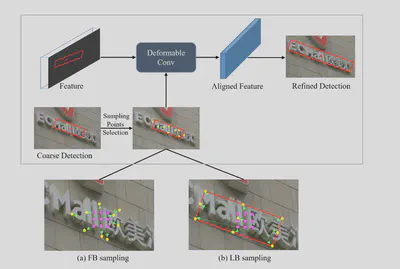
TFAM的结构如下。首先生成粗检测结果,然后将粗检测结果和特征传入变形卷积层中。其中变形卷积选择采样点有两种方式,分别是Feature-Based Sampling和Localization-Based Sampling。其中,前者是使用额外的卷积来计算采样点的偏移量,后者是直接使用当前点预测的粗检测框的位置作为偏移后的采样点。
本文中提出的Position-awareness NMS与EAST中的locality-awareness NMS不同。在EAST中进行的NMS是,是利用加权平均的方式,使用Text/Non-Text分类的结果作为权值进行加权和然后进行正常的NMS。
本文中提出的PA-NMS基于一个假设,距离边界越近的点,得到的距离边界的距离越准确,因此在聚合的时候使用的权重为当前点距离边界的位置。当使用边框p和q聚合得到m时,计算过程如下。其中TBLR分别为EAST输出的Geo-Map的四个通道,即Position-Awareness Map。
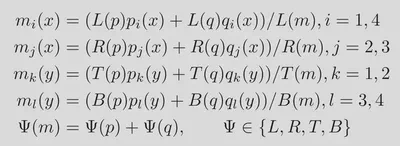
其中Position-Awareness Map(相当于EAST中的Geo-Map归一化到0-1)的生成方式如下。
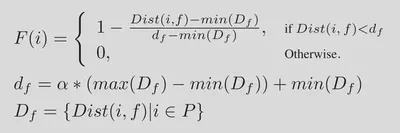
在损失函数的选择上,原本EAST中使用IoU-Loss。但是文中提到如下观点。因此引入了Instance-wise IoU Loss。
the large text region contains far more positive samples than the small text region, which makes the regression loss bias towards large and long text instances.
其中$N_t$为Text Instance的数量,$S_j$为每个Text Instance中Positive Sample的数量。(这里我没有很清楚具体Text Instance和Positive Sample的定义,为理解为对于每一个Text/Non-Text分类为真的点都要计算IoU,对于面积比较大的文本计算IoU的次数比较多,导致模型偏重大文本和长文本。)
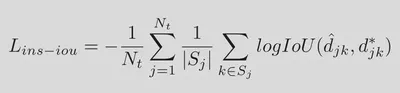
最终的损失函数定义如下,完整的损失包括分类损失、检测损失、位置损失。分类损失使用BCE-Loss计算,位置损失使用Smoothed L1-Loss计算。在检测损失中包括了检测结果的IoU-Loss和边界框角度的Cosine-Loss。 $$\begin{align} L &= L_s + \lambda_{gc} L_{gc} + \lambda_{gr} L_{gr}+ \lambda_{p} L_{p} \\ L_s &= \operatorname{BCE-Loss}() \\ L_g &= L_{iou} + \lambda_{i} L_{ins-iou} + \lambda_{\theta} L_{\theta} \\ L_{\theta} &= \frac{1}{|\Omega|}\sum\limits_{i \in \Omega}1-\cos (\hat{\theta_i} - \theta_i^*) \\ L_p &= \frac{1}{4|\Omega|}\sum\limits_{i \in \Omega}\sum\limits_{\Psi \in \{L,R,T,B\}}\operatorname{SmoothedL1}(\hat{\Psi_i}-\Psi_i^*) \end{align}$$
结果分析
在数据集SynthText上预训练,在数据集MLT17、MTWI、IC15、MSRA-TD500(with HUST-TR400)上训练和测试。
在Ablation Study中,证明Localization-Based Sampling相比Feature-Based Sampling效果更好,而同时结合这两种的效果最好。同时也证明了本文中提出的TFAM、PA-NMS、Instance-wise IoU Loss都能提升模型的性能。
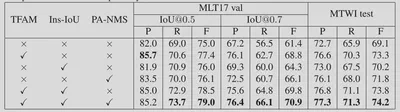
在与SOTA模型的比较中,MOST也都能获得不错的性能提升。
总结
为了解决长文本的检测问题,引入了TFAM扩展感受野修正粗检测结果。 为了解决不同大小的文本的检测问题,引入了Instance-wise IoU Loss,防止损失函数过度关注大文本和长文本目标。 在NMS阶段引入了Position-Aware NMS,可以更好的合并检测框。