OCRNet
Jul 6, 2022·
·
1 min read
ECCV2020提出的一种上下文信息融合方式。
主要是使用与当前位置类别相同的区域的特征来增强当前位置的表示。与DeepLab中的ASPP相比效果更好。
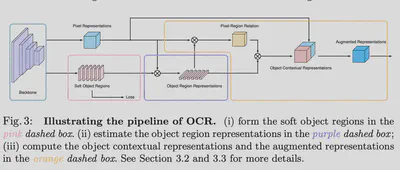
在论文中指出这样的方法和使用Transformer 模块的结构相似,都使用了Self-Attention 自注意力。
图中Soft Object Regions是利用分割Loss监督的K通道粗分割结果,Pixel Representation是Backbone得到的C通道特征,使用矩阵相乘直接得到$B\times C \times K$的关系矩阵,使用特征作为Q,关系矩阵作为K和V,通过$softmax(\frac{Q^TK}{\sqrt{d_k}})V$计算得到增强后的特征,与原本的特征相连接用于分割。
这篇论文和HRNet是同一个团队做的,因此HRNet+OCR已经称为一种非常强分割Backbone。代码放到了github。
在文章中,作者提出了一种改进Segmentation Transformer,同时被NVIDIA的团队改进,提出了《HIERARCHICAL MULTI-SCALE ATTENTION FOR SEMANTIC SEGMENTATION》。
当SegFix出现之后,也经常使用HRNet+OCR+SegFix作为比赛中常用的分割Backbone。