【论文】Shape Robust Text Detection with Progressive Scale Expansion Network
论文题目:Shape Robust Text Detection with Progressive Scale Expansion Network
作者:Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, Shuai Shao
会议/时间:CVPR2019
链接:arxiv
论文目标
在当前的文字检测算法在应用时有两个问题:当前的算法通常得到一个四边形边界框,难以检测任意形状的文本;如果两行文本距离比较近,有可能会被框选为同一个边界框。因此提出了PSENet,可以有效的解决上述的两个问题。
相关工作
现有的基于CNN的文本检测模型可以分为两类:基于回归的方案和基于分割的方案。前者生成四边形的边界框,无法处理任意形状的文本,后者使用像素级的分类得到目标区域,但是很难区分开相聚比较近的目标。
基于回归的文本检测方案大多是基于通用的目标检测模型,包括Faster R-CNN等。其他的文本检测模型还有TextBoxes、EAST等。大多数这一类的模型都需要设计Anchor而且由多个处理阶段组成,可能会导致性能比较差。基于分割的文本检测方案主要使用FCN,例如通过FCN获得热力图等,再进行后处理获得文本位置。
本文思路/解决方案
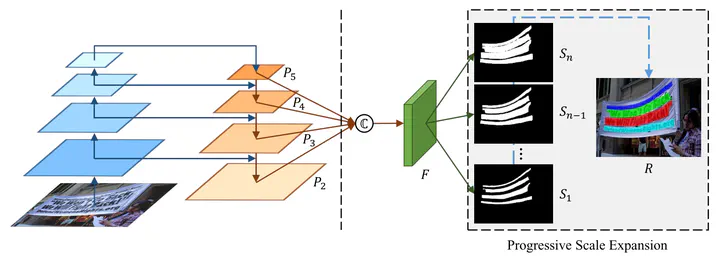
本文提出的PSENet是基于分割的方案,每一个预测的分割称为kernel,形状相似但是大小不同,最后设计了一个基于BFS的渐进扩展算法,将原本的kernel扩展得到最终的预测分割。由于使用渐近扩展式的算法,对于最小尺寸的kernel,可以区分开距离较近的文本,同时也可以解决小尺寸分割难以覆盖完整文本的问题。
模型结构是基于ResNet的FPN结构,从中选取不同大小的特征图连接得到混合特征图,最后通过卷积等操作得到不同尺寸的多个分割图,再经过尺寸扩展得到预测结果。
在这个尺寸扩展算法中,首先选择了尺寸最小的分割图进行连通域分析作为kernel,然后将其他的分割图作为输入,通过Scale Expansion算法计算新的扩展后的kernel,最终得到结果。作者提到对于位于多个文本之间的像素,使用先来先服务的方式合并到不同的标签中,同时由于使用了渐进式的方法,这些边界上的重合并不会影响最终的处理结果,这可能也是作者选择多个不同尺寸的分割图渐近处理的原因。

在训练过程中,为了获得不同尺寸的分割图,需要提供对应的标签供学习,作者使用了Vatti clipping algorithm来将最初的文本框标签收缩一定的像素得到这些标签。算法中使用到的像素值通过下面的公式计算得到。其中m为最小的缩放比例,n为不同尺寸的分割图的个数。
$$\begin{aligned} d_i = \frac{\mathrm{Area}(p_n)\times(1-r_i^2)}{\mathrm{Perimeter}(p_n)}\notag\\ r_i = 1 - \frac{(1-m)\times(n-i)}{n-1} \end{aligned}$$在实验中作者使用了Dice Coefficient作为模型的评价指标,使用了完整尺寸的标签和缩放后的标签上的Dice系数作为损失函数来指导模型的学习。其中对于完整尺寸的标签,使用Online Hard Example Mining(OHEM)来获得一个mask协助训练。 $$\begin{aligned} L &= \lambda L_c + (1-\lambda)L_s\notag\\ L_c &= 1 - D(S_n\cdot M, G_n \cdot M)\notag\\ L_s &= 1 - \frac{\sum\limits^{n-1} D(S_i\cdot W, G_i \cdot W)}{n-1}\notag\\ W_{x,y} &= \left\{ \begin{align} 1,& \quad if\ S_{n,x,y} \geq0.5;\notag\\ 0,& \quad otherwise\notag\\ \end{align} \right. \end{aligned}$$
结果
实验包括了四个数据集:CTW1500、Total-Text、ICDAR2015和ICDAR2017MLT。模型使用预训练好的ResNet,在IC17-MLT上训练,而且没有使用另外的人造数据集。实验讨论的结果包括:
- 最小尺寸的kernel并不能直接作为模型的输出,模型的F-measure结果比较差,而且文本框内容的识别结果也比较差。
- 对于最小缩放比例m的选择,选择太大或者太小都会导致性能的下降。
- 分割图的个数n增加时,性能会有一定的上升,但是不能无限制增大,在n大于5之后性能提升不大。
- 修改模型骨架,例如增加ResNet的层数也会提升模型的性能。
总结
使用了基于FPN的结构,将不同尺度的特征图上采样并连接在一起。
获得不同尺度下的分割图,再从小到大渐进式的合并,不仅可以检测到任意形状的文本,也可以避免将距离比较近的文本识别为同一对象。