【论文】Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
主要内容
构建了一种残差网络结构,有利于深度神经网络的训练,同时证明了该残差网络结构更容易优化并且在深度增加时仍能实现较高的准确率。同时训练了一个152层的网络用语图像识别。
背景
传统的用于图像识别的DCNN通过增加深度可以提高识别性能。但是会出现梯度爆炸/消失的现象(vanishing/exploding gradient)。
通过引入正则化等方法可以使深度网络实现收敛(SGD)。尽管可以收敛,但深度增加时会出现性能下降(degradation)。
因此文中实现了一种残差网络deep residual learning,用来解决degradation问题。
主要方式为:要学习得到H(x),构造F(x)=H(x)-x并学习,最终得到F(x)+x即为所学习的目标。这里的+x可以使用短接(shortcut connection:跳过若干层的连接)来实现。这样的操作相当于恒等映射,没有引入新的参数或计算复杂度。
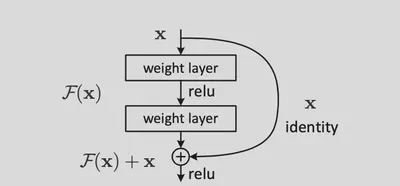
实现
通过使用短接可以使得非线性的网络更好的拟合恒等映射,即令网络参数为0。
因此构造的网络形如 $y = F(x,{W_i})+x$ 。使用两层网络和ReLU构造网络块得到 $F = W_2\sigma(W_1x)$,其中 $\sigma$表示ReLU,最终的输出为 $\sigma{y}$。可以添加一个矩阵 $W_s$ 用于将F的输出和x的规模对齐。
这里F的结构可以使用两层或三层网络,但是不能只有一层(实际上构成一个线性单元)。同时每一层的结构可以是全联接层也可以是卷积层。
类比VGG-19网络,构造一个34层的深度卷积神经网络,以及其对应的深度残差网络。其中后河通过在前者的网络结构中每隔两层添加一个短路连接得到。
评价
相对于普通的深度网络,深度残差网络更容易训练。
相对于相同深度的网络,深度残差网络可以得到更高的准确度。
当网络深度增加时,使用深度残差网络可以缓减错误率上升的情况。
短路连接使用不同的方式(直接映射/规模不同时使用矩阵/全部使用矩阵)可以带来轻微的性能提升,但直接映射的复杂度比较低。