2021分割新进展
扫了一些分割方面论文,截止日期2021-12-29
针对结构的修改
专注于设计新的模块和现有网络结构的扩展。
CNN
Lanyun Zhu在CVPR2021提出的“Learning Statistical Texture for Semantic Segmentation”。基本骨架是普通的CNN提取网络加上[[DeepLab 系列]]中的ASPP。同时引入了两个新的模块TEM和PTFEM,从CNN最底层的特征图中学习纹理特征,TEM进行纹理增强,PTFEM利用计数算子QCO学习金字塔纹理特征。最后上采样得到分类,得到STLNet。
Xing Shen在CVPR2021提出的“DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation”。使用了基于DCT变换的Mask表示,相比基于像素的表示降低了复杂度和计算量。
FCN/UNet
Chen Guan学长在ITFS2020年发的“Lip image segmentation based on a fuzzy convolutional neural network”。主要是还是在FCN的基础上,在特征融合的部分添加了一个Fuzzy Block进行特征的融合。
Ruigang Niu在ITGRS上发的“Improving Semantic Segmentation in Aerial Imagery via Graph Reasoning and Disentangled Learning”在特征backbone的基础上,不同大小的特征图使用图推断+上采样,进行concate,用双流的结构分别进行前景先验估计和边缘对齐,然后合并进行分割预测。
Xia Li在CVPR2020上发的“Spatial Pyramid Based Graph Reasoning for Semantic Segmentation”也是利用了U-Net和图卷积的方式
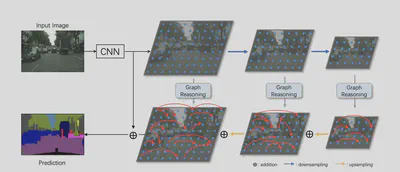
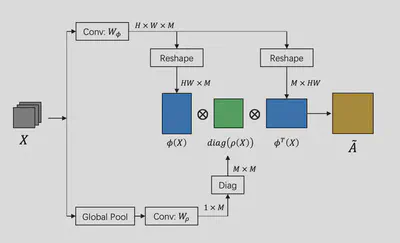
Yunpeng Chen在CVPR2019上发的“Graph-Based Global Reasoning Networks”设计了一个图推断模块,将特征映射到图空间,使用GCN进行推断然后再映射回到原本的坐标空间中,可以插在FCN模型之后的位置,提升模型性能。
Zilong Zhong在CVPR2020上发的“Squeeze-and-Attention Networks for Semantic Segmentation”对SE-Net中的SE模块进行改进,使得在分割任务中的效果更好。
Yanwei Li在CVPR2020上发的“Learning Dynamic Routing for Semantic Segmentation”使用了动态路径选择的方法,
Transformer
Sixiao Zheng在CVPR2021发的“Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers”提出了SETR,将transformer应用到了图像分割中。首先进行划分patch和linear projection,然后通过24个transformer,最后通过reshape和卷积上采样得到像素级分类结果。
针对目标场景
3D点云数据
Na Zhao在CVPR2021发的“Few-shot 3D Point Cloud Semantic Segmentation”提出一种Few-Shot的学习方法,结合Attention Learner和Metric Learner得到特征,然后使用图构造进行预测。
多光谱数据
RGB-T数据,包含可见光和热成像数据,属于多模态学习。
Qiang Zhang在CVPR2021发的“ABMDRNet: Adaptive-weighted Bi-directional Modality Difference Reduction Network for RGB-T Semantic Segmentation”使用双流的方式,首先使用MDRF(Modality Difference Reduction and Fusion)进行Image2Image的转换,减少两个模态数据的差异,然后使用CWF,MSC,MCC三个模块进行合并再解码得到分类结果。MSC(Spatial Context)中使用了ASPP和Non-Local的结构。MCC利用了Channel Context。
人体语义解析
Tianfei Zhou在CVPR2021发的:“Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing”进行多粒度的人体结构解析。使用自下而上的方式,实现Instance级别的结果。
视频解析
由于我们的目标是视频数据,传统的做法是使用降采样然后对每一帧进行单独的处理,但是直觉上来看,时序上下文信息应该对于分割有一定的帮助,例如相邻帧的变化比较小的时候,上一帧中嘴唇的位置,在下一帧也大概率是嘴唇。
Ping Hu在CVPR2020发的“Temporally Distributed Networks for Fast Video Semantic Segmentation”提出了一种视频语义分割的快速网络,对每一帧使用轻量级网络提取特征然后在时序上聚合得到完整的特征进行语义分割。
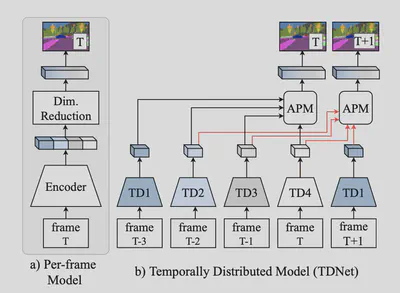
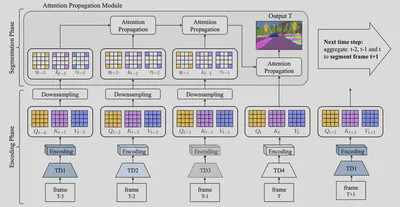
Si Liu在CVPR2017发的“Surveillance Video Parsing with Single Frame Supervision”也使用了多帧的光流等信息进行分割性能的增强。
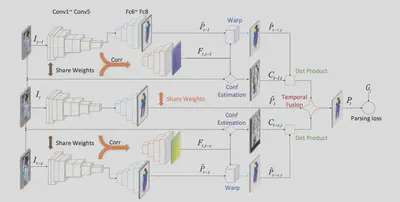
Haochen Wang在CVPR2021发的“SwiftNet: Real-time Video Object Segmentation”使用多帧信息解决VOS(Video Object Segmentation)问题。但是实际上VOS问题的定义是,对于一个视频流,在最开始的一帧分割得到目标,然后自动在后面的t帧中将相同目标检测并分割出来。
针对训练方法
持续学习
模型训练好之后,增加了新的分类类别,称为持续学习。分割领域中称为CSS(Continual Semantics Segmentation)。
Arthur等人在CVPR2021发的“PLOP: Learning without Forgetting for Continual Semantic Segmentation”设计了一种新的蒸馏机制POD,保留了空间信息,在CSS过程中能够不忘记旧数据中的特征。
元学习/无监督域适应
无监督域适应(Unsupervised Domain Adaption)
Xiaoqing Guo在CVPR2021发的“MetaCorrection: Domain-aware Meta Loss Correction for Unsupervised Domain Adaptation in Semantic Segmentation”设计了一种元学习框架。
Few-Shot
弱监督半监督
Xun Xu等在CVPR2020上提出的“Weakly Supervised Semantic Point Cloud Segmentation: Towards 10x Fewer Labels”可以只使用几个像素的大致标注信息进行训练。
损失函数优化
Xiaofeng Liu在CVPR2020上提出的“Severity-Aware Semantic Segmentation with Reinforced Wasserstein Training”为分割过程中的不同类型的误分类指定不同的代价。这个代价矩阵是通过强化学习的方式和Wasserstein距离的定义来导出的。