Enhancing the Security of Visual Speaker Authentication Based on Dynamic Lip-Print Analysis
Mar 3, 2026·
·
0 min read
Abstract
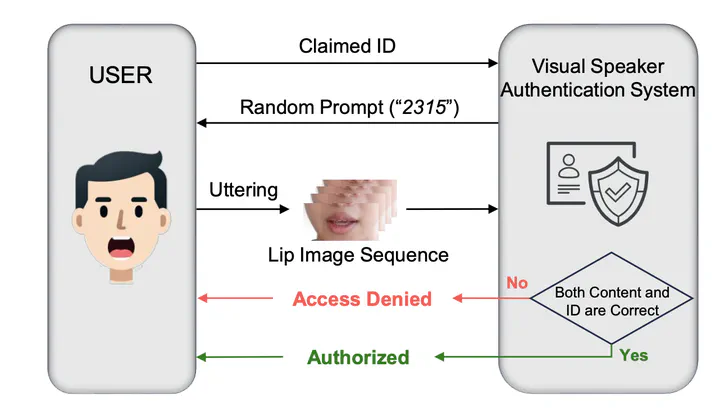
In recent years, face-based authentication methods are gradually replacing traditional methods across various applications, offering enhanced security and user convenience. However, these methods are threatened by the continuously evolving DeepFake techniques. In this paper, a novel Visual Speaker Authentication (VSA) approach based on dynamic lip-prints is proposed to improve system security against diverse attacks. The lip-prints are discriminative viseme segments that capture user’s localized speaking habits. By leveraging these dynamic lip-prints, this approach can expand the prompt set without requiring additional user-recordings or model retraining, thereby strengthening resilience to replay attacks. Moreover, a Multi-Layer Dynamic-Enhanced Encoder is introduced to model fine-grained lip dynamics, addressing data scarcity challenges and ensuring robust feature extraction even in scenarios with short temporal spans and limited enrollment data. We have carried out extensive experiments on several datasets and the results have demonstrated the effectiveness of the proposed method in both security enhancement and prompt set scalability.
Type
Publication
In The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026