Cascade-Free Mandarin Visual Speech Recognition via Semantic-Guided Cross-Representation Alignment
Mar 3, 2026·
·
0 min read
Abstract
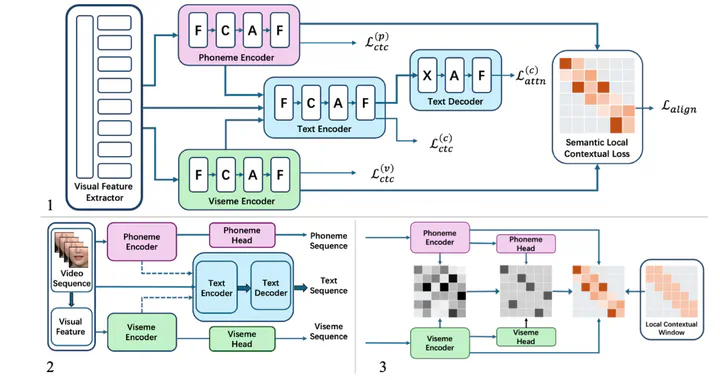
Chinese mandarin visual speech recognition (VSR) is a task that has advanced in recent years, yet still lags behind the performance on non-tonal languages such as English. One primary challenge arises from the tonal nature of Mandarin, which limits the effectiveness of conventional sequence-to-sequence modeling approaches. To alleviate this issue, existing Chinese VSR systems commonly incorporate intermediate representations, most notably pinyin, within cascade architectures to enhance recognition accuracy. While beneficial, in these cascaded designs, the subsequent stage during inference depends on the output of the preceding stage, leading to error accumulation and increased inference latency. To address these limitations, we propose a cascade-free architecture based on multitask learning that jointly integrates multiple intermediate representations, including phoneme and viseme, to better exploit contextual information. The proposed semantic-guided local contrastive loss temporally aligns the features, enabling on-demand activation during inference, thereby providing a trade-off between inference efficiency and performance while mitigating error accumulation caused by projection and re-embedding. Experiments conducted on publicly available datasets demonstrate that our method achieves superior recognition performance.
Type
Publication
In 2026 IEEE International Conference on Multimedia and Expo.